Model-Specific vs Model-Agnostic Explainers
Contents
Model-Specific vs Model-Agnostic Explainers#
Synonyms: Not Generalizable vs Generalizable Explanations.
In brief#
We distinguish between model-specific or model-agnostic explanation methods depending on whether the technique adopted to retrieve the explanation acts on a particular model adopted by an AI system, or can be used on any type of AI.
More in detail#
This is one of the first Dimensions of Explanations we should consider.
The most used approach to explain AI black boxes is known as reverse engineering. The name comes from the fact that the explanation is retrieved by observing what happens to the output, i.e., the AI decision, when changing the input in a controlled way. An explanation method is model-specific, or not generalizable [2], whether it considers inputs or outputs as well as the inner-workings of a machine learning model. The drawback of this approach is that it can be used to interpret only particular types of black box models. For example, if an explanation approach is designed to interpret a Random Forest [3] and internally uses a concept of distance between trees, then such an approach cannot be used to explain the predictions of a neural network.
On the other hand, an explanation method is model-agnostic, or generalizable, when it can be used independently from the black box model being explained. In other words, the AI’s internal characteristics are not exploited to build the interpretable model approximating the black box behavior.
In Fig. 9, there is a summarization of these two kinds of approaches.
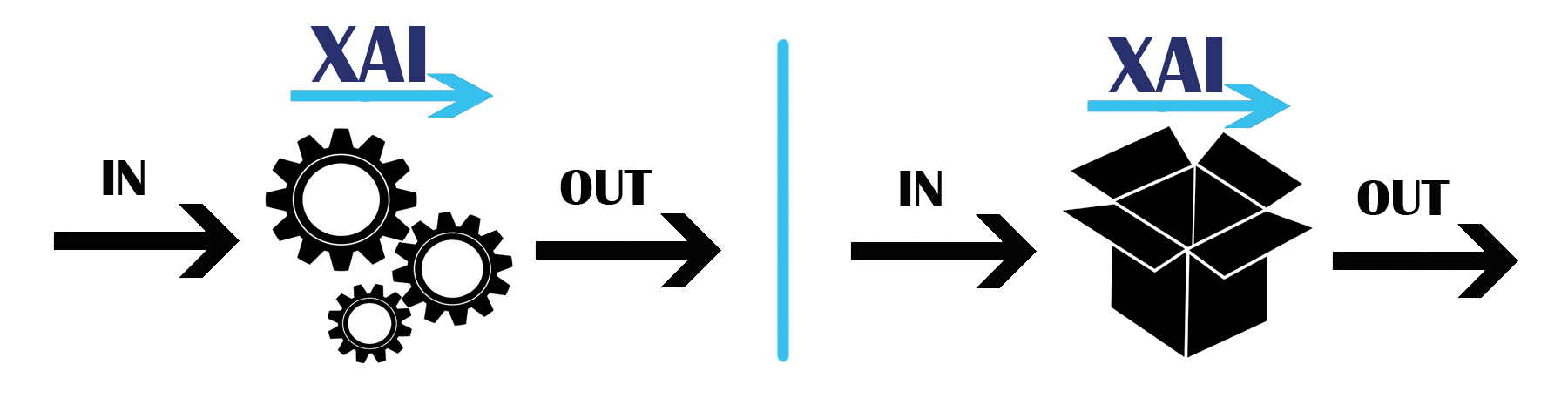
Fig. 9 On the left, an explainer which exploites the internal structure and behaviour of the model. On the right, an explainer which uses the model as a black-box to understand its reasoning.#
Bibliography#
- 1
Pang-Ning Tan, Michael Steinbach, and Vipin Kumar. Introduction to data mining. Pearson Addison-Wesley, 2006.
- 2
David Martens, Bart Baesens, Tony Van Gestel, and Jan Vanthienen. Comprehensible credit scoring models using rule extraction from support vector machines. European journal of operational research, 183((3)):1466––1476, 2007.
This entry was readapted from Guidotti, Monreale, Pedreschi, Giannotti. Principles of Explainable Artificial Intelligence. Springer International Publishing (2021) by Francesca Pratesi and Riccardo Guidotti.