Respect for Privacy
Contents
Respect for Privacy#
In Brief#
Respect for Privacy is an ethical aspect studied in the TAILOR project for ensuring personal data protection that is at the core of the General Data Protection Regulation (GDPR) [1]. GDPR, in its Article 5, promote privacy by design in the form of a certain number of general principles for ensuring privacy as the default in the whole chain of data processing for a given task. We outline the challenges and solutions for enforcing privacy by design approaches.
Abstract#
When protecting personal data, we are faced to the dilemma of disclosing no sensitive data while learning useful information about a population. One approach for solving this tension between privacy and utility is based on data encryption and consists in developping secure computation protocols able to learn models or to compute statistics on encrypted data. A lot of scientific literature [2] [3] [4] [5] has been exploring this security-based approach depending on the target computational task. Another approach consists in conducting data analysis tasks on datasets made anonymous by the application of some ./L1.privacy_mechanisms. according to some Privacy Models. Anonymization must no be reduced to Pseudonymization (see also Re-identification Attack), which is defined in GDPR Article 4 as “the processing of personal data in such a way that the data cannot be attributed to a specific data subject without the use of additional information.” Anonymization, as defined in GDPR (see Recital 26), refers to a process that removes any possibility of identifying a person even with additional information. In the resulting anonymized data, the connection should be completely lost between data and the individuals. Based on such a definition, anonymization is very difficult to model formally and to verify algorithmically. We will briefly survey the main privacy models and their properties, as well as the main privacy mechanisms which can be applied for enforcing the corresponding privacy properties or for providing strong guarantees of robustness to attacks.
Motivation and Background#
Publishing datasets plays an essential role in open data research and in promoting transparency of government agencies. Unfortunately, the process of data publication can be highly risky as it may disclose individuals’ sensitive information. Hence, an essential step before publishing datasets is to remove any uniquely identifiable information from them. This is called Pseudonymization and consists in masking or replacing by pseudonyms values of properties that directly identify persons such as their name, address, postcode, telephone number, photograph or image, or some other unique personal characteristic.
Pseudonymization is not sufficient however for preserving the privacy of users. Adversaries can re-identify individuals in datasets based on common attributes called quasi-identifiers or may have prior knowledge about the users. Such side information enables them to reveal sensitive information that can cause physical, financial, and reputational harms to people.
Therefore, it is crucial to assess carefully privacy risks before the publication of datasets. Detection of privacy breaches should come with explanations that can then be used to guide the choice of the appropriate anonymization mechanisms to mitigate the detected privacy risks. Anonymization should provide provable guarantees for privacy properties induced by some Privacy Models. Differential Privacy and k-anonymity are the two main privacy models for which ./L1.privacy_mechanisms have been designed. They enjoy different properties based on the type of perturbations or transfomations applied on the data to anonymize.
The strength of Pseudonymization and anonymization techniques can be assessed by their robustness to privacy attacks that aim at re-identifying individuals in datasets based on common attributes called quasi-identifiers or on prior knowledge.
Guidelines#
EDBP has published several guidelines. The EDPB Guidelines on Data Protection Impact Assessment focus on determining whether a processing operation is likely to result in a high risk to the data subject or not. It provides guidance on how to assess data protection risks and how to carry out a data protection risk assessment.
Data minimisation is a strong recommendation to limit the collection of personal information to what is directly relevant and necessary to accomplish a specified purpose, and to retain the data only for as long as is necessary to fulfil that purpose.
The most authoritative guideline on data protection “by design and by default” outlines the data subject’s rights and freedoms and the data protection principles that are illustrated through examples of practical cases. It emphasizes the obligation for controllers to stay up to date on technological advances on handling data protection risks, and to implement and update the measures and safeguards taking into account the evolving technological landscape.
Software Frameworks Supporting Dimension#
There are some practical tools that help in enanching respect for privacy and awareness, in particular definining and mitigating potential privacy risks. This is compliant with the Data Protection Impact Assessment introduced in the GDPR.
Risks can be identified and addressed at an early stage by analyzing how the proposed uses of personal information and technology will work in practice. We should identify the privacy and related risks, evaluate the privacy solutions and integrate them into the project plan.
Currently, a lot of frameworks have implemented to manage this task. University of British Colombia provides a tool for determining a project’s privacy and security risk classification. TrustArc offers a consulting service for analyzing personally identifiable information, looking at risk factors and assisting in the development of policies and training programs. Information Commissioner’s Office provides a handy step by step guide through the process of deciding whether to share personal data12. Also the US Department of Homeland Security implemented such decision tool.
A (non-exhaustive) list of more practical tools includes:
Amnesia, a tool for anonymize tabular data relying on k-anonymity paradigm;
AXR, a tool that incorporates different Privacy Models;
Scikit-mobility, a Python library for mobility analysis that includes the computation of privacy risks in such setting, based on the work presented in [6] [7].
Taxonomic Organisation of Terms#
The Respect for Privacy dimension mainly regards the Data Protection. The Assessment of Privacy Risks can be performed, and two diffent strategies are available two protect the data privacy. The first one regards the application of Anonymization Mechanisms, such as Pseudonymization, k-anonymity, or Differential Privacy. The second strategy is Data Encryption, which is strictly related with the Security Dimension. In Fig. 18, one can find the taxonomy proposed here. In blue, there are highlighted the possible attacks related to the various strategies, i.e., Re-identification Attack, ./L2.membership, and Security Attacks.
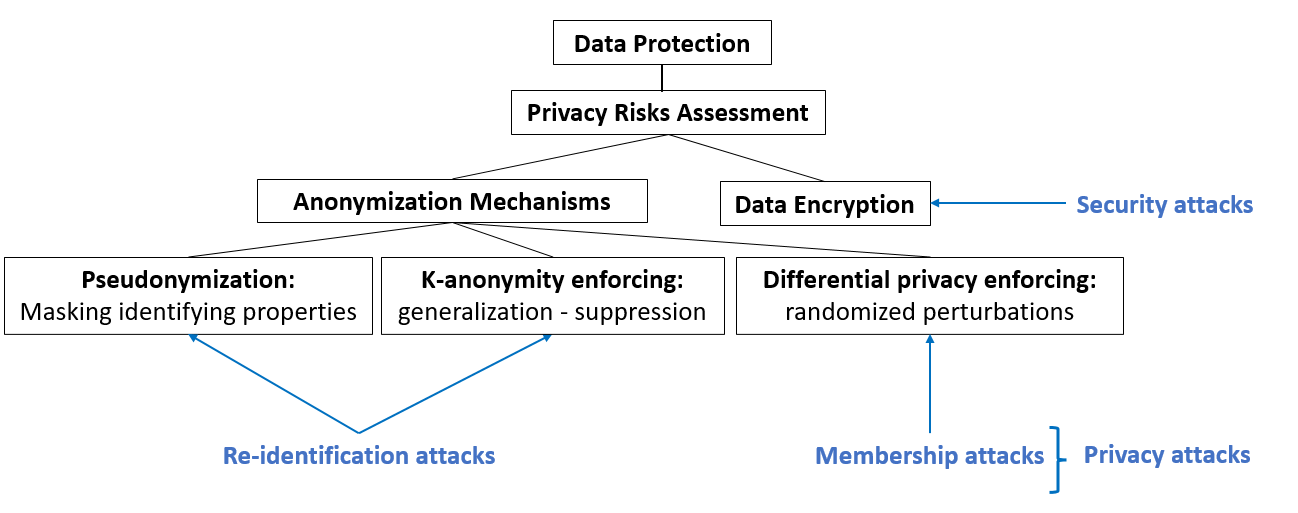
Fig. 18 A possible taxonomy about solutions to the Respect for Privacy dimension.#
Main Keywords (TBA)#
Data Anonymization (and Pseudonymization): A data subject is considered anonymous if it is reasonably hard to attribute his personal data to him/her.
Pseudonymization: Pseudonymisation aims to substitute one or more identifiers that link(s) the identity of an individual to its data with a surrogate value, called pseudonym or token.
Privacy Models: There are essentially two families of models, based on different goals and mechanisms: anonymity by randomization (where the most recent paradigm is Differential Privacy) and anonymity by indistinguishability (whose most famous example is k-anonymity).
Differential Privacy: Differential privacy implies that adding or deleting a single record does not significantly affect the result of any analysis.
\epsilon-Differential Privacy: \(\epsilon\)-Differential Privacy is the simpler form of Differential Privacy, where \(\epsilon\) represents the level of privacy guarantee.
(\epsilon,\delta)-Differential Privacy: A relaxed version of Differential Privacy, named (\(\epsilon\),\(\delta\))-Differential Privacy, allows a little privacy loss (\(\delta\)) due to a variation in the output distribution for the privacy mechanism.
Achieving Differential Privacy: Differential privacy guarantees can be provided by perturbation mechanisms aim at randomizing the output distributions of functions in order to provide privacy guarantees.
k-anonymity: k-anonimity (and the whole family of anonymity by indistinguishability models) is based on comparison among individuals present in data, and it aims to make each individual so similar as to be indistinguishable from at least k-1 others.
Attacks on anonymization schemes: There are a variety of attacks that involve data privacy. Some of them are very context-specific (for example, there exists attacks on partition-based algorithms, such as deFinetti Attack or Minimality Attack), while other are more general.
Re-identification Attack: Re-identification attack aims to link a certain set of data related to an individual in a dataset (which does not contain direct identifiers) to a real identity, relying on additional information.
Bibliography#
- 1
European Parliament & Council. General data protection regulation. 2016. L119, 4/5/2016, p. 1–88.
- 2
C. Castelluccia, A. C.-F. Chan, E. Mykletun, and G. Tsudik. Efficient and Provably Secure Aggregation of Encrypted Data in Wireless Sensor Networks. ACM Transactions on Sensor Networks (TOSN), 5(3):20:1–20:36, 2009.
- 3
Q.-C. To, B. Nguyen, and P. Pucheral. Private and Scalable Execution of SQL Aggregates on a Secure Decentralized Architecture. ACM Transactions on Database Systems (TODS), 41(3):16:1–16:43, 2016.
- 4
J. Mirval, L. Bouganim, and I. Sandu Popa. Practical Fully-Decentralized Secure Aggregation for Personal Data Management Systems. In International Conference on Scientific and Statistical Database Management (SSDBM), 259–264. 2021.
- 5
R. Ciucanu, M. Giraud, P. Lafourcade, and L. Ye. Secure Grouping and Aggregation with MapReduce. In International Joint Conference on e-Business and Telecommunications (ICETE) – Volume 2: International Conference on Security and Cryptography (SECRYPT), 514–521. 2018.
- 6
Luca Pappalardo, Filippo Simini, Gianni Barlacchi, and Roberto Pellungrini. Scikit-mobility: a python library for the analysis, generation and risk assessment of mobility data. 2019. https://arxiv.org/abs/1907.07062.
- 7
Francesca Pratesi, Anna Monreale, Roberto Trasarti, Fosca Giannotti, Dino Pedreschi, and Tadashi Yanagihara. PRUDEnce: a system for assessing privacy risk vs utility in data sharing ecosystems. Transaction Data Privacy, 11(2):139–167, 2018.
This entry was written by Marie-Christine Rousset, Tristan Allard, and Francesca Pratesi.