Evaluation
Contents
Evaluation#
Synonyms: Assessment, Testing, Measurement.
In brief#
AI measurement is any activity that estimates attributes as measures— of an AI system or some of its components, abstractly or in particular contexts of operation. These attributes, if well estimated, can be used to explain and predict the behaviour of the system. This can stem from an engineering perspective, trying to understand whether a particular AI system meets the specifications or the intention of their designers, known respectively as verification and validation. Under this perspective, AI measurement is close to computer systems testing (hardware and/or software) and other evaluation procedures in engineering. However, in AI there is an extremely complex adaptive behaviour, and in many cases, with a lack of a written and operational specification. What the systems has to do depends on some constraints and utility functions that have to be optimised, is specified by example (from which the system has to learn a model) or ultimately depends on feedback from the user or the environment (e.g., in the form of rewards).
More in detail#
AI measurement has been taken place since the early days of AI and has framed the discipline very significantly. Actually, one of the foundational ideas behind AI is the famous imitation game [2], which —somewhat misleadingly— is usually referred to as the Turing test. However, this initial emphasis on evaluation, albeit mostly philosophical, did not develop into technical AI evaluation as an established subfield in AI, in the same way the early Reliability and Robustness problems in software engineering led to the important areas of software validation, verification and testing, today using both theoretical and experimental approaches [5, 3]. Still, there are some recent surveys and books covering the problem of AI evaluation, and giving comprehensive or partial views of AI measurement, such as [4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14].
The tradition in AI measurement turns around the concept of ‘task-oriented evaluation’. For instance, given a scheduling problem, a board game or a classification problem, systems are evaluated according to some metric of task performance. To standardise the comparisons among systems, there are datasets and benchmarks that are used for evaluating these systems, so that evaluation data is not cherry-picked by the AI designers. We find a myriad of examples of the latter in PapersWithCode1 (PwC), an open-source, community-centric platform which offers researchers access to hundreds of benchmarks and thousands of results from associated papers, with an emphasis on machine learning. PwC collects information about the performance of different AI systems during a given period, typically ranging from the introduction of the benchmark to the present day. Figure 22 shows an example of the evolution of results for ImageNet[15].
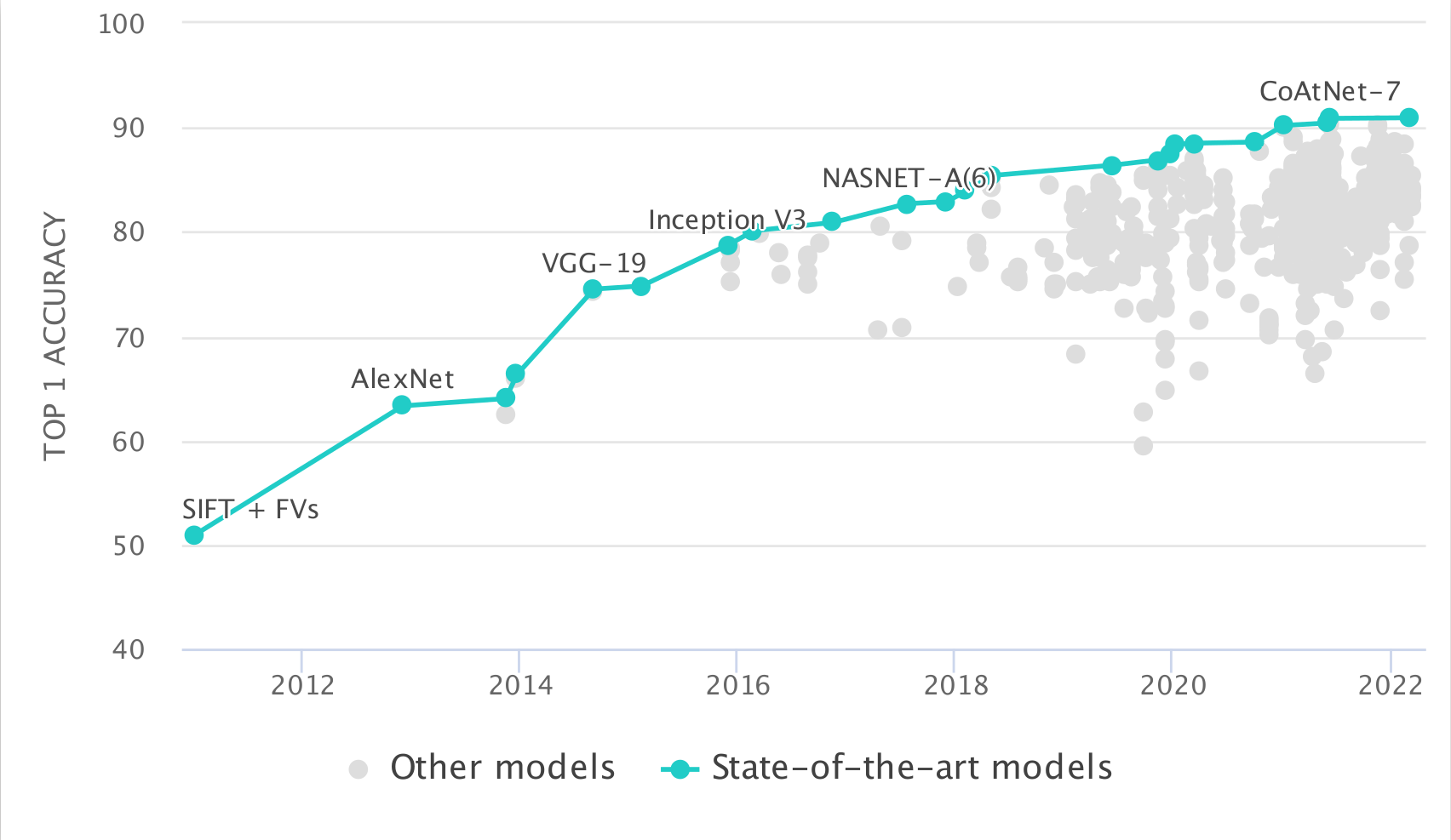
Fig. 22 State-of-the-Art for the image classification task using the benchmark ImageNet. The points represent the accuracy of all the attempts from 2011 to 2022. The connected points on the Pareto front are shown in blue. Chart from https://paperswithcode.com/sota/image-classification-on-imagenet#
However, the focus on particular benchmarks (which are known by the researchers in advance) and the power of machine learning techniques has led to a problem of benchmark specialisation, a phenomenon that is related to issues such as “teaching to the test” (students prepare for the test but do not know how to solve cases that differ slightly from those of the exam) or Goodhart’s or Campbell’s laws (optimising to the indicator may lead to the metric not measuring what it measured originally, with possibly some other side effects). One clear manifestation of this phenomenon is the ‘challenge-solve-and-replace’ evaluation dynamics [16] or a ‘dataset-solve-and-patch’ adversarial benchmark co-evolution [17], which means that as soon as a benchmark is released, performance grows quickly because researchers specialise the design and training of the system to the benchmark, but not to the general task [11]. Ultimately the benchmark needs to be replaced by another one (usually more complex or adversarially designed), in a continuous cycle.
This task-oriented evaluation has been blamed for some of the failures or narrowness of AI in the past —lack of common sense, of generality, of adaptability to new contexts and distributions. As we said, since the beginning of the discipline, other approaches for AI measurement have been used or proposed. These include the Turing test, and endless variants [18, 19], the use of human tests, from science exams [20] to psychometric tests [21, 22, 23], the adaptation of psychophysics [24] or item response theory [25], the use of collections of video games [26], the exploration of naive physics [27], or the adaptation of tests from animal cognition [28]. All these approaches attempt to measure intelligence more broadly, some general cognitive abilities or at least skills that could be applied to a range of different tasks. Accordingly, these fall under the paradigm of ‘capability-oriented evaluation’ [4].
The key difference between performance and capability is that performance is affected by the distribution, while capability is not. For instance, the same individual (an AI system or a human) can have different degrees of performance for the same task or set of tasks if we change the distribution of examples (e.g., by including more difficult examples), but the capability should be the same, since it should be a property of an individual. If a person or computer has the capability of resolving simple negation, this capability is not changed by including many double negations in the dataset, even if this decreases performance. However, identifying and estimating the level for different capabilities is much more challenging than measuring performance. Also, drawing conclusions about the cognitive abilities of AI systems requires caution, even from the most-well designed experiments. But this is also true even when performance is used as a proxy for capability [29].
Bibliography#
- 1
John D Musa, Anthony Iannino, and Kazuhira Okumoto. Software reliability. Advances in computers, 30:85–170, 1990.
- 2
A.M. Turing. Computing machinery and intelligence. Mind, 59(236):433, 1950.
- 3
W Richards Adrion, Martha A Branstad, and John C Cherniavsky. Validation, verification, and testing of computer software. ACM Computing Surveys (CSUR), 14(2):159–192, 1982.
- 4(1,2)
José Hernández-Orallo. Evaluation in artificial intelligence: from task-oriented to ability-oriented measurement. Artificial Intelligence Review, 48(3):397–447, 2017.
- 5
J. Hernández-Orallo. The Measure of All Minds: Evaluating Natural and Artificial Intelligence. Cambridge University Press, 2017.
- 6
José Hernández-Orallo, Marco Baroni, Jordi Bieger, Nader Chmait, David L Dowe, Katja Hofmann, Fernando Martínez-Plumed, Claes Strannegård, and Kristinn R Thórisson. A new AI evaluation cosmos: ready to play the game? AI Magazine, 2017.
- 7
Chris Welty, Praveen Paritosh, and Lora Aroyo. Metrology for AI: from benchmarks to instruments. arXiv preprint arXiv:1911.01875, 2019.
- 8
Peter Flach. Performance evaluation in machine learning: the good, the bad, the ugly and the way forward. In AAAI. 2019.
- 9
Peter Flach. Measurement theory for data science and AI: modelling the skills of learning machines and developing standardised benchmark tests. Turing Institute, https://www.turing.ac.uk/research/research-projects/measurement-theory-data-science-and-ai, 2019.
- 10
Guillaume Avrin. Evaluation of artificial intelligence systems. Laboratoire National de Métrologie et d’Essais : https://www.lne.fr/en/testing/evaluation-artificial-intelligence-systems, 2019.
- 11(1,2)
Jose Hernandez-Orallo. Ai evaluation: on broken yardsticks and measurement scales. In AAAI Workshop on Evaluating Evaluation of AI Systems. 2020.
- 12
Fernando Martínez-Plumed and José Hernández-Orallo. Dual indicators to analyze ai benchmarks: difficulty, discrimination, ability, and generality. IEEE Transactions on Games, 12(2):121–131, 2020. doi:10.1109/TG.2018.2883773.
- 13
José Hernández-Orallo. Identifying artificial intelligence capabilities: what and how to test. 2021.
- 14
Jose Hernandez-Orallo, Wout Schellaert, and Fernando Martinez-Plumed. Training on the test set: mapping the system-problem space in ai. AAAI Senior Member Track - Blue Sky Ideas, 2022.
- 15
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: a large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, 248–255. Ieee, 2009.
- 16
David Schlangen. Language tasks and language games: on methodology in current natural language processing research. arXiv preprint arXiv:1908.10747, 2019.
- 17
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
- 18
G. Oppy and D. L. Dowe. The Turing Test. In Edward N. Zalta, editor, Stanford Encyclopedia of Philosophy. 2011. Stanford University, http://plato.stanford.edu/entries/turing-test/.
- 19
José Hernández-Orallo. Twenty years beyond the turing test: moving beyond the human judges too. Minds and Machines, 30(4):533–562, 2020.
- 20
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789, 2018.
- 21
S. Bringsjord and B. Schimanski. What is artificial intelligence? Psychometric AI as an answer. In International Joint Conference on Artificial Intelligence, 887–893. 2003.
- 22
D. L. Dowe and J. Hernandez-Orallo. IQ tests are not for machines, yet. Intelligence, 40(2):77–81, 2012. URL: http://www.sciencedirect.com/science/article/pii/S0160289611001619, doi:10.1016/j.intell.2011.12.001.
- 23
J. Hernández-Orallo, F. Mart\'ınez-Plumed, U. Schmid, M. Siebers, and D. L. Dowe. Computer models solving human intelligence test problems: progress and implications. Artificial Intelligence, 230:74–107, 2016.
- 24
Joel Z Leibo and others. Psychlab: a psychology laboratory for deep reinforcement learning agents. arXiv preprint arXiv:1801.08116, 2018.
- 25
Fernando Martínez-Plumed, Ricardo BC Prudêncio, Adolfo Martínez-Usó, and José Hernández-Orallo. Item response theory in AI: analysing machine learning classifiers at the instance level. Artificial Intelligence, 271:18–42, 2019.
- 26
Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: an evaluation platform for general agents. Journal of Artificial Intelligence Research, 47:253–279, 2013.
- 27
Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, and Ross Girshick. Phyre: a new benchmark for physical reasoning. Advances in Neural Information Processing Systems, 2019.
- 28
Benjamin Beyret, José Hernández-Orallo, Lucy Cheke, Marta Halina, Murray Shanahan, and Matthew Crosby. The animal-ai environment: training and testing animal-like artificial cognition. arXiv preprint arXiv:1909.07483, 2019.
- 29
Ryan Burnell, John Burden, Danaja Rutar, Konstantinos Voudouris, Lucy Cheke, and José Hernández-Orallo. Not a number: identifying instance features for capability-oriented evaluation. IJCAI, 2022.
This entry was written by Jose Hernandez-Orallo, Fernando Martinez-Plumed, Santiago Escobar, and Pablo A. M. Casares.