Black Box Explanation vs Explanation by Design
Contents
Black Box Explanation vs Explanation by Design#
Synonyms: Post-hoc vs Ante-hoc Explanations, Explainable vs Interpretable Artificial Intelligence
In brief#
The difference between Black Box Explanation (or Post-hoc Explanations) and Explanation by Design (or Ante-hoc Explanations) regards the ability to know and exploit the behaviour of the AI model. With a black box explanation, we pair the black box model with an interpretation the black box decisions or model, while in the second case, the strategy is to rely, by design, on a transparent model.
More in detail#
The precise definitions of the core concepts in these fields – such as transparency, interpretability and explainability – remain elusive, in part because these notions tend to be domain-specific [2].
When we talk about Black Box Explanation, the strategy is to couple an AI with a black box model with an explanation method able to interpret the black box decisions. Usually, this situation is associated with systems that are proprietary – hence inaccessible – or too complicated to understand [3].
In the case of Explanation by Design (aka Transparency), the idea is to substitute the obscure model with a transparent model in which the decision process is accessible by design, i.e., explainability is inserted into a model from the very beginning. Interpretability presupposes an observer who appraises the intelligibility of the model in question. This indicates that interpretability is not a binary property, but it is rather determined by the degree to which one can understand the system’s operations, and thus resides on a spectrum of opaqueness [4].
In view of this fluidity, the distinction between ante-hoc interpretability and post-hoc explainability techniques commonly made in the literature becomes blurred. Post-hoc explainability offers insights into the behaviour of a predictive system by building an additional explanatory model that interfaces between it and human explainees (i.e., explanation recipients). This is the only approach compatible with black-box systems, with which we can interact exclusively by manipulating their inputs and observing their outputs. Such an operationalisation is nonetheless unsuitable for high stakes domains since the resulting explanations are not guaranteed to be reliable and truthful with respect to the underlying model [3]. Ante-hoc explainability, in contrast, often refers to data-driven systems whose model form adheres (in practice) to application- and domain-specific constraints – a functional definition – which allows their designers to judge their trustworthiness and communicate how they operate to others [3]. While the post-hoc moniker is, in general, used consistently across the literature, the same is not true for the ante-hoc label; the interpretability and explainability terms are also often mixed and used interchangeably, adding to the confusion. Ante-hoc sometimes refers to, among other things, transparent models that are self-explanatory, systems that are inherently interpretable, scenarios where the explanation and the prediction come from the same model, and situations where the model itself (or its part) constitutes an explanation, which are vague terms that are often incompatible with the functional definition of ante-hoc interpretability [4]. Nonetheless, all of these notions presuppose an observer to whom the model is interpretable and who understands its functioning, which brings us back to the issue of accounting for an audience and its background.
Figure 7 depicts this distinction.
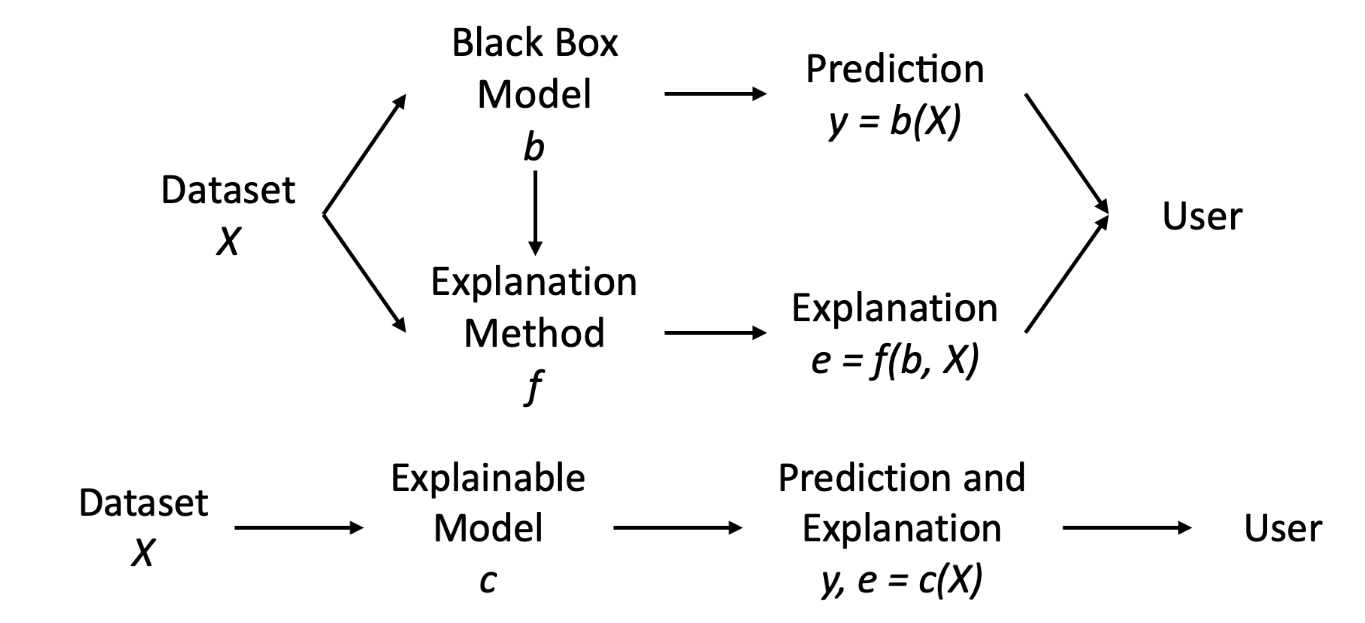
Starting from a dataset X, the black box explanation idea is to maintain the high performance of the obscure model b used by the AI, which is allowed to be trained normally, and to use an explanation method f to retrieve an explanation e by reasoning over b and X. In such a way, we aim to reach both accuracy and the ability to gain some Kinds of Explanations. This kind of approach is the one more addressed nowadays in the XAI research field [5] [6] [7].
On the other hand, the explanation by design consists of directly designing a comprehensible model c over the dataset X, which is interpretable by design and returns an explanation e besides the prediction y. Thus, the idea is to use this transparent model directly in the AI system [3] [8]. In the literature, there are various models recognized to be interpretable. Examples include decision trees, decision rules, and linear models [9]. These models are considered easily understandable and interpretable for humans. However, nearly all of them sacrifice performance in favor of interpretability. In addition, they cannot be applied effectively on data types such as images or text, but only on tabular, relational data, i.e., tables.
The functional definition of ante-hoc interpretability concerns the engineering aspects of information modelling and its adherence to domain-specific knowledge and constraints. A transparent model may be ante-hoc interpretable to its engineers and domain experts with relevant technical knowledge, yet it may not engender understanding in explainees outside this milieu. For example, a decision tree is transparent, but its interpretability presupposes its small size as well as technical understanding of its operation and familiarity with the underlying data domain; one way to restore interpretability to a large tree is to process its structure to extract decision rules, exemplars and counterfactuals.
Bibliography#
- 1
Riccardo Guidotti, Anna Monreale, Dino Pedreschi, and Fosca Giannotti. Principles of Explainable Artificial Intelligence. Springer International Publishing, 2021.
- 2
Kacper Sokol and Peter Flach. Explainability is in the mind of the beholder: establishing the foundations of explainable artificial intelligence. arXiv preprint arXiv:2112.14466, 2021.
- 3(1,2,3,4)
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence, 1(5):206–215, 2019.
- 4(1,2)
Kacper Sokol and Julia E Vogt. (un)reasonable allure of ante-hoc interpretability for high-stakes domains: transparency is necessary but insufficient for comprehensibility. In 3rd Workshop on Interpretable Machine Learning in Healthcare (IMLH) at 2023 International Conference on Machine Learning (ICML). 2023.
- 5
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. Why should i trust you?: explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1135–1144. ACM, 2016.
- 6
Mark Craven and Jude W Shavlik. Extracting tree-structured representations of trained networks. In Advances in neural information processing systems, 24–30. 1996.
- 7
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Advances in neural information processing systems, 4765–4774. 2017.
- 8
Cynthia Rudin and Joanna Radin. Why are we using black box models in ai when we don’t need to? a lesson from an explainable ai competition. Harvard Data Science Review, 2019.
- 9
Alex A Freitas. Comprehensible classification models: a position paper. ACM SIGKDD explorations newsletter, 15(1):1–10, 2014.
- 10
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. In Advances in neural information processing systems, 4349–4357. 2016.
This entry was partially readapted from Guidotti, Monreale, Pedreschi, Giannotti. Principles of Explainable Artificial Intelligence. Springer International Publishing (2021) by Francesca Pratesi, Riccardo Guidotti, and Kacper Sokol.