Saliency Maps
Contents
Saliency Maps#
In brief#
Saliency maps are explanations used on image classification tasks. A saliency map is an image where each pixel’s color represents a value modeling the importance of that pixel in the original image (i.e., the one given in input to the explainer) for the prediction.
More in detail#
The most used type of explanation for explaining AI systems working on images consists of saliency maps. A saliency map is an image where each pixel’s color represents a value modeling the importance of that pixel for the prediction, i.e., they show the positive (or negative) contribution of each pixel to the black box outcome. Saliency maps are a very typical example of local explanation methods since they are tailored to the image that must be explained.
In the literature, there exist different explanation methods locally explaining deep neural networks for image classification. The two most used model-specific techniques are perturbation-based attribution methods [6, 7] and gradient attribution methods such as sal [8], elrp [9], grad [10], and intg [11].
Without entering into the details, these XAI approaches aim at attributing an importance score to each pixel in order to minimize the probability of the deep neural network (DNN) labeling the image with a different outcome when only the most important pixels are considered. Indeed, the areas retrieved by these methods are also called attention areas.
The aforementioned XAI methods are specifically designed for specific DNN models, i.e., they are model-specific.
However, relying on appropriate image transformations that take advantage of the concept of “superpixels” [1], i.e., the results of the segmentation of an image into regions by considering proximity or similarity measures, also model-agnostic explanation methods (such as lime [1], anchor [5], and lore [12]) can be employed to explain AI working on images for any kind of black box model.
The attention areas of explanations returned by these methods are strictly dependent on both:
the technique used for segmenting the image to explain and
to a neighborhood consisting of unrealistic synthetic images with “suppressed” superpixels [13].
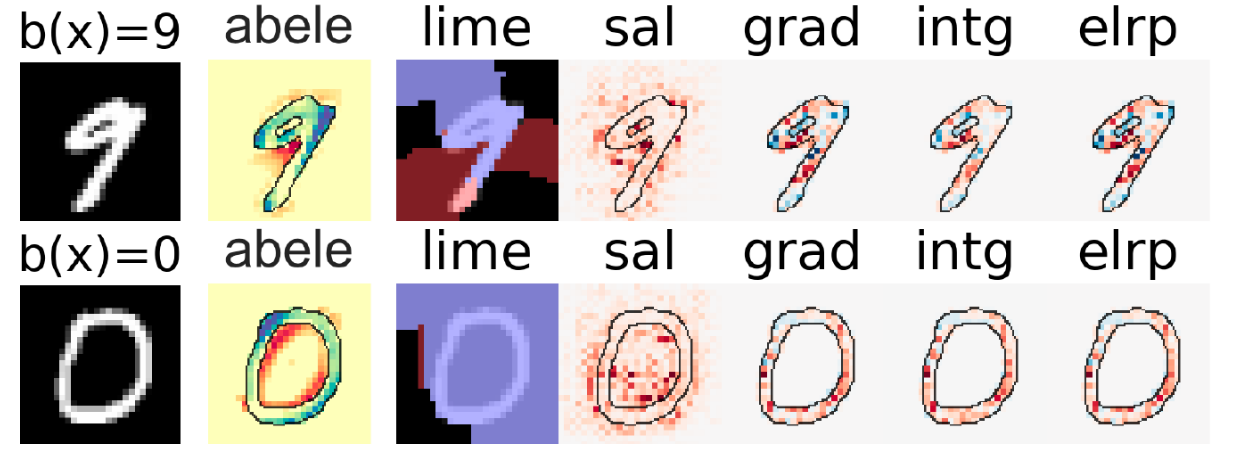
A different approach for generating neighborhoods is introduced by the local model-agostic explanation method abele [3]. This method relies on a generative model, i.e., an adversarial autoencoder [14], to produce a realistic synthetic neighborhood that allows retrieving more understandable saliency maps. Indeed, saliency maps returned by abele highlight the contiguous attention areas that can be varied while maintaining the same classification from the black box used by the AI system.
Fig. 19 reports a comparison of saliency maps for the classification of the handwritten digits “9” and “0” for the explanation methods abele [3, 4], lime [1], sal [8], elrp [9], grad [10], and intg [11].
Bibliography#
- 1(1,2,3)
M.T. Ribeiro, S. Singh, and C. Guestrin. "why should I trust you?": explaining the predictions of any classifier. In SIGKDD. 2016.
- 2
Riccardo Guidotti, Anna Monreale, Dino Pedreschi, and Fosca Giannotti. Principles of Explainable Artificial Intelligence. Springer International Publishing, 2021.
- 3(1,2)
Riccardo Guidotti, Anna Monreale, Stan Matwin, and Dino Pedreschi. Black box explanation by learning image exemplars in the latent feature space. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, 189–205. Springer, 2019.
- 4
Riccardo Guidotti, Anna Monreale, Fosca Giannotti, Dino Pedreschi, Salvatore Ruggieri, and Franco Turini. Factual and counterfactual explanations for black box decision making. IEEE Intelligent Systems, 34(6):14–23, 2019.
- 5
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. Anchors: high-precision model-agnostic explanations. In Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
- 6
Ruth C Fong and Andrea Vedaldi. Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision, 3429–3437. 2017.
- 7
Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In European conference on computer vision, 818–833. Springer, 2014.
- 8(1,2)
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034, 2013.
- 9(1,2)
Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PloS one, 10(7):e0130140, 2015.
- 10(1,2)
Avanti Shrikumar, Peyton Greenside, Anna Shcherbina, and Anshul Kundaje. Not just a black box: learning important features through propagating activation differences. arXiv preprint arXiv:1605.01713, 2016.
- 11(1,2)
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. arXiv preprint arXiv:1703.01365, 2017.
- 12
Riccardo Guidotti, Anna Monreale, Salvatore Ruggieri, Dino Pedreschi, Franco Turini, and Fosca Giannotti. Local rule-based explanations of black box decision systems. 2018. https://arxiv.org/abs/1805.10820.
- 13
Riccardo Guidotti, Anna Monreale, and Leonardo Cariaggi. Investigating neighborhood generation methods for explanations of obscure image classifiers. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, 55–68. Springer, 2019.
- 14
Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, Ian Goodfellow, and Brendan Frey. Adversarial autoencoders. arXiv preprint arXiv:1511.05644, 2015.
This entry was readapted from Guidotti, Monreale, Pedreschi, Giannotti. Principles of Explainable Artificial Intelligence. Springer International Publishing (2021) by Francesca Pratesi and Riccardo Guidotti.