Prototypes
Contents
Prototypes#
Synonyms: Exemplars.
In Brief#
Prototype-based explanation methods return as explanation a selection of particular instances of the dataset for locally explaining the behavior of the AI system [2].
More in details#
Prototypes (or exemplars) make clear to the user the reasons for the AI system’s decision. In other words, prototypes are used as a foundation of representation of a category, or a concept [4]. A concept is represented through a specific instance. Prototypes help humans in constructing mental models of the black box model and of the training data used. Prototype-based explainers are generally local methods that can be used independently for tabular data, images, and text. Obviously, prototype-based explanations only make sense if an instance of the data is humanly understandable and makes sense as an explanation. Hence, these methods are particularly useful for images, short texts, and tabular data with few features.
In [5], prototypes are selected as a minimal subset of samples from the training data that can serve as a condensed view of a data set. Naive approaches for selecting prototypes use the closest neighbors from the training data with respect to a predefined distance function, or the closest centroids returned by a clustering algorithm []. In [6], authors designed a sophisticated model-specific explanation method that directly encapsulates in a deep neural network architecture an autoencoder and a special prototype layer, where each unit of that layer stores a weight vector that resembles an encoded training input. The autoencoder permits to make comparisons within the latent space and to visualize the learned prototypes such that, besides accuracy and reconstruction error, the optimization has a term that ensures that every encoded input is close to at least one prototype. Thus, the distances in the prototype layer are used for the classification such that each prediction comes with an explanation corresponding to the closest prototype. In [7], prototypical parts of images are extracted by a ProtoPNet network, such that each classification is driven by prototypical aspects of a class.
Although prototypes are representative of all the data, sometimes they are not enough to provide evidence for the classification without instances that are not well represented by the set of prototypes [2]. These instances are named criticisms and help to explain what is not captured by prototypes. In order to aid human interpretability, in [8] prototypes and criticisms are selected by means of the Maximum Mean Discrepancy (mmd): instances in highly dense areas are good prototypes, instances which are in regions that are not well explained by the prototypes are selected as criticisms. Finally, the abele method [3] enforces the saliency map explanation with a set of exemplar and counter-exemplar images, i.e., images similar to the one under investigation classified for which the same decision is taken by the AI, and images similar to the one explained for which the black box of the AI returns a different decision. The particularity of abele is that it does not select exemplars and counter-exemplars from the training set, but it generates them synthetically exploiting an adversarial autoencoder used during the explanation process [9]. An example of exemplars (left) and counter-exemplars (right) is shown in Figure {numref}`{number} fig:prototypes.
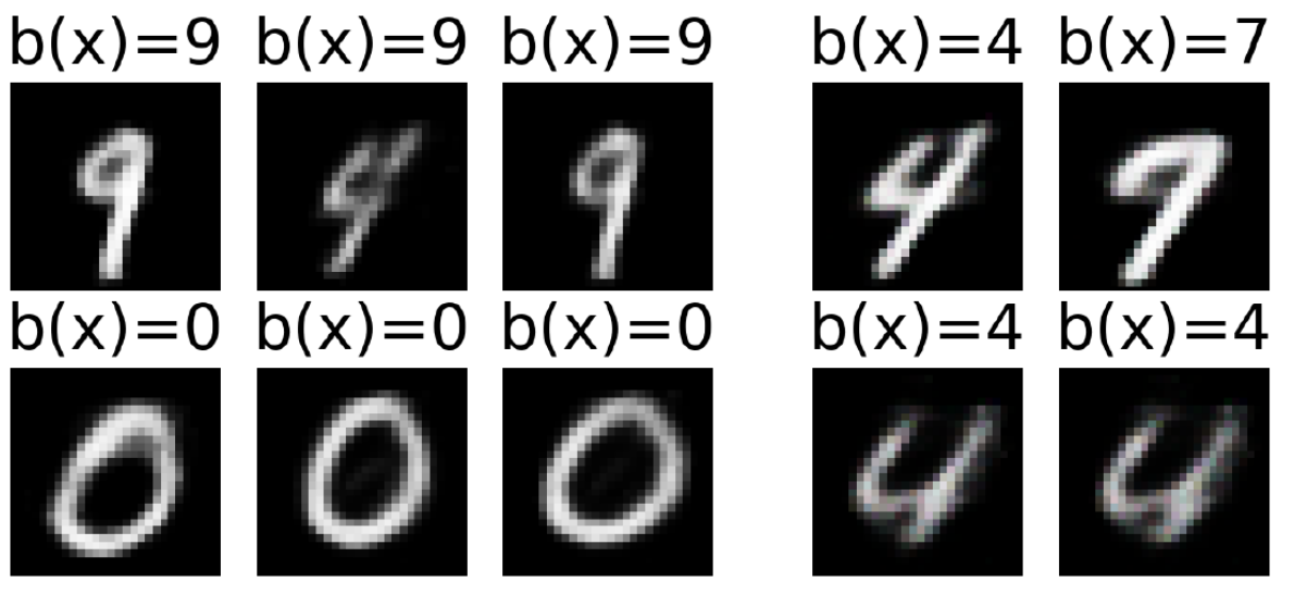
Bibliography#
- 1
Riccardo Guidotti, Anna Monreale, Dino Pedreschi, and Fosca Giannotti. Principles of Explainable Artificial Intelligence. Springer International Publishing, 2021.
- 2(1,2)
Christoph Molnar. Interpretable Machine Learning. Lulu. com, 2020.
- 3
Riccardo Guidotti, Anna Monreale, Stan Matwin, and Dino Pedreschi. Black box explanation by learning image exemplars in the latent feature space. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, 189–205. Springer, 2019.
- 4
Marcello Frixione and Antonio Lieto. Prototypes vs exemplars in concept representation. In KEOD, 226–232. 2012.
- 5
Jacob Bien and Robert Tibshirani. Prototype selection for interpretable classification. The Annals of Applied Statistics, pages 2403–2424, 2011.
- 6
Oscar Li, Hao Liu, Chaofan Chen, and Cynthia Rudin. Deep learning for case-based reasoning through prototypes: a neural network that explains its predictions. In Thirty-second AAAI conference on artificial intelligence. 2018.
- 7
Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, and Jonathan K Su. This looks like that: deep learning for interpretable image recognition. In Advances in neural information processing systems, 8930–8941. 2019.
- 8
Been Kim, Rajiv Khanna, and Oluwasanmi O Koyejo. Examples are not enough, learn to criticize! criticism for interpretability. In Advances in neural information processing systems, 2280–2288. 2016.
- 9
Orestis Lampridis, Riccardo Guidotti, and Salvatore Ruggieri. Explaining sentiment classification with synthetic exemplars and counter-exemplars. In International Conference on Discovery Science, 357–373. Springer, 2020.
This entry was readapted from Guidotti, Monreale, Pedreschi, Giannotti. Principles of Explainable Artificial Intelligence. Springer International Publishing (2021) by Francesca Pratesi.