Explainable AI
Contents
Explainable AI#
In Brief#
Explainable AI (often shortened to XAI) is one of the ethical dimensions that is studied in the TAILOR project. The origin of XAI dates back to the entering into force of the General Data Protection Regulation (GDPR). The GDPR [1], in its Recital 71, also mentions the right to explanation, as a suitable safeguard to ensure fair and transparent processing in respect of data subjects. It is defined as the right “to obtain an explanation of the decision reached after profiling”. According to NIST report [2], an explanation is the evidence, support, or reasoning related to a system’s output or process, where the output of a system differs by task, and the process refers to the procedures, design, and system workflow which underlie the system.
Abstract#
While other aspects of ethics and trustworthiness, such as Respect for Privacy, are not novel concepts, and a lot of scientific literature has been explored on these topics, the study of explainability is a new challenge. In this part, we will cover the main elements that define the explanation of AI systems. First, we will try to survey briefly the main guidelines related to explainability. Then, we summarize a taxonomy that can be used to classify explanations. We will define the possible Dimensions of Explanations (e.g., we can discriminate between Model-Specific vs Model-Agnostic Explainers). Next, we will describe the requirements to provide good explanations and some of the problems related to the Explainability topic. Finally, we will give some examples of possible solutions we can adopt to provide explanations describing the reasoning behind an ML/AI model.
Motivation and Background#
So far, the usage of black boxes in AI and ML processes has implied the possibility of inadvertently making wrong decisions due to a systematic bias in training data collection. Several practical examples have been provided, highlighting the “bias in, bias out” concept. One of the most famous examples of this concept regards a classification task: the algorithm’s goal was to distinguish between photos of Wolves and Eskimo Dogs (huskies) [1]. Here, the training phase of the process was done with 20 images, hand-selected such that all pictures of wolves had snow in the background, while pictures of huskies did not. This choice was intentional because it was part of a social experiment. In any case, on a collection of additional 60 images, the classifier predicts “Wolf” if there is snow (or light background at the bottom), and “Husky” otherwise, regardless of animal color, position, pose, etc (see an example in Fig. 1).

Fig. 1 Raw data and explanation of a bad model’s prediction in the “Husky vs Wolf” task [1]. On the right, there is the original image; on the left, there is the explanation of the classification.#
However, one of the most worrisome cases was discovered and published by ProPublica, an independent, nonprofit newsroom that produces investigative journalism with moral force. In [4], the authors showed how software can actually be racist. In a nutshell, the authors analyzed a tool called COMPAS (which stands for Correctional Offender Management Profiling for Alternative Sanctions). COMPAS tries to predict, among other indexes, the recidivism of defendants, who are ranked low, medium, or high risk. It was used in many US states (such as New York and Wisconsin) to suggest to judges an appropriate probation or treatment plan for individuals being sentenced. Indeed, the tool was quite accurate (around 70 percent overall with 16,000 probationers), but ProPublica journalists found that black defendants were far more likely than white defendants to be incorrectly judged to be at a higher risk of recidivism, while white defendants were more likely than black defendants to be incorrectly flagged as low risk.
From the above examples, it appears evident that explanation technologies can help companies for creating safer, more trustable products, and better managing any possible liability they may have.
Open the Black-Box Problem#
The Open the Black Box Problems for understanding how a black box works can be summarized in the taxonomy proposed in [1] and reported in Fig. 2. The Open the Black Box Problems can be separated from one side as the problem of explaining how the decision system returned certain outcomes (Black Box Explanation) and on the other side as the problem of directly designing a transparent classifier that solves the same classification problem (Transparent Box Design). Moreover, the Black Box Explanation problem can be further divided among Model Explanation when the explanation involves the whole logic of the obscure classifier, Outcome Explanation when the target is to understand the reasons for the decisions on a given object, and Model Inspection when the target to understand how internally the black box behaves changing the input.
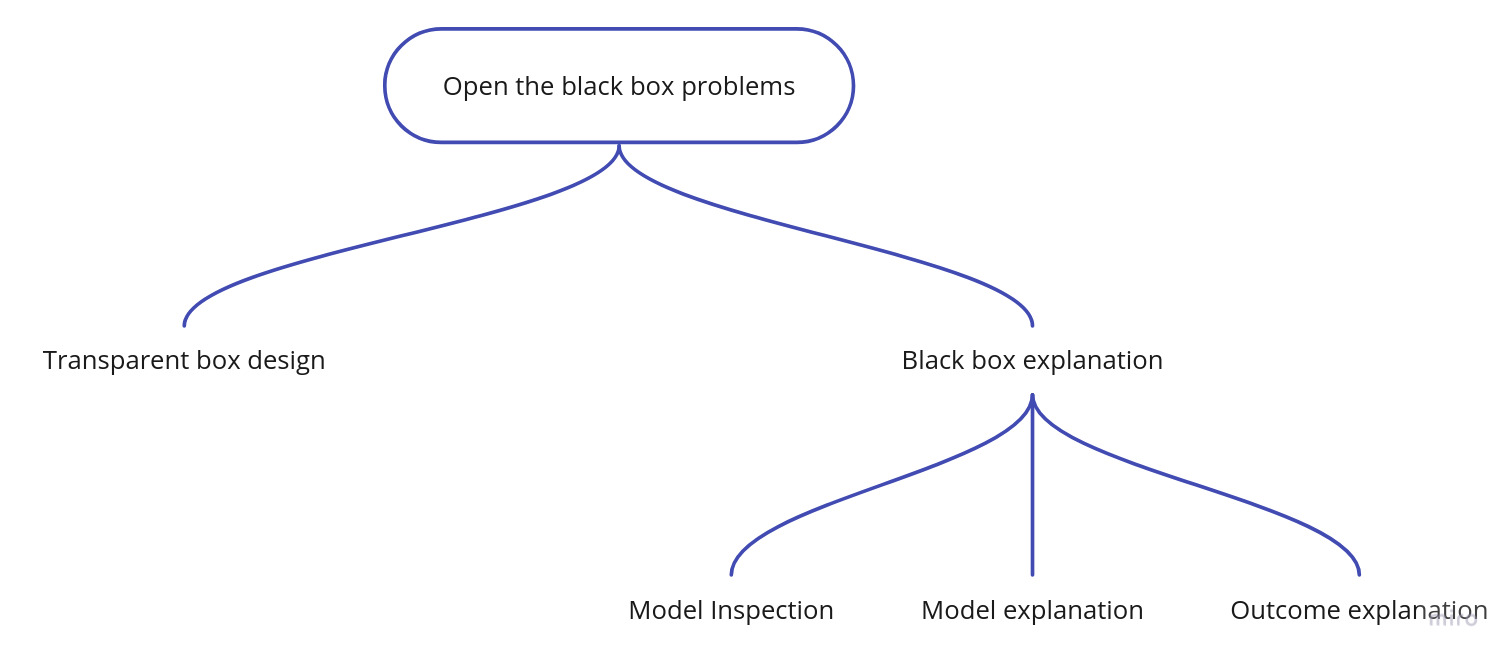
On a different dimension, a lot of effort has been put into defining what are the possible Dimensions of Explanations (e.g., we can discriminate between Model-Specific vs Model-Agnostic Explainers), the requirements to provide good explanations (see guidelines), how to evaluate explanations, and to understand the Feature Importance. Then, it is important to note that a variety of different kinds of explanations can be provided, such as Single Tree Approximation, Feature Importance, Saliency Maps, Factual and Counterfactual, Exemplars and Counter-Exemplars, and Rules List and Rules Sets.
Guidelines#
Given the relative novelty of the topic, a lot of guidelines have been developed in recent years.
However, the most authoritative guideline is the High-Level Expert Group on Artificial Intelligence - Ethics Guidelines for Trustworthy AI. Here, the explainability topic is included in the broader transparency. According to this guideline, explainability concerns the ability to explain both the technical processes of an AI system and the related human decisions (e.g., application areas of a system). Following the GDPR interpretation, in [1], it is stated that whenever an AI system has a significant impact on people’s lives, it should be possible to demand a suitable explanation of the AI system’s decision-making process. Such explanation should be timely and adapted to the expertise of the stakeholder concerned (e.g., layperson, regulator, or researcher). In addition, explanations of the degree to which an AI system influences and shapes the organizational decision-making process, design choices of the system, and the rationale for deploying it, should be available (hence ensuring business model transparency).
Another distinguished authority that has been worked on ethical guidance is the Alan Turing Institute, the UK’s national institute for data science and artificial intelligence, where David Leslie [7] summarized the risks due to the lack of transparency or the absence of a valid explanation, and he advocates the use of counterfactuals for contrasting unfair decisions. Together with the Information Commissioner’s Office (ICO), which is responsible for overseeing data protection in the UK, it has been published more recent and complete guidance [8]. Here, six steps are recommended to develop a system:
Select priority explanations by considering the domain, use case, and impact on the individual.
Collect and pre-process data in an explanation-aware manner, stressing the fact that the way in which data is collected and pre-processed may affect the quality of the explanation.
Build systems to ensure to being able to extract relevant information for a range of explanation types.
Translate the rationale of your system’s results into useable and easily understandable reasons, e.g., transforming the model’s logic from quantitative rationale into intuitive reasons or using everyday language that can be understood by non-technical stakeholders.
Prepare implementers to deploy the AI system, through appropriate training.
Consider how to build and present the explanation, particularly keeping in mind the context and contextual factors (domain, impact, data, urgency, audience) to deliver appropriate information to the individual.
Nevertheless, the attention on this theme is not relegated to the European border. Indeed, as an example of US effort in dealing with Explainability and Ethics, NIST, the National Institute of Standards and Technology of Maryland, developed some guidelines, and a white paper [2] was published after a first draft1 was published in 2020, a variety of comments2 was collected, and a workshop3 involving different stakeholders was held. The white paper [2] analyzes the multidisciplinary nature of explainable AI and acknowledges the existence of different users who requires different kinds of explanations, stating that one-size-fits-all explanations do not exist. The fundamental properties of explanations contained in the report are:
Meaningfulness, i.e., explanations must be understandable to the intended consumer(s). This means that there is the need to consider the intended audience and some characteristics they can have, such as prior knowledge or the overall psychological differences between people. Moreover, the explanation’s purpose is relevant too. Indeed, different scenarios and needs impact on what is important and useful in a given context. This implies understanding the audience’s needs, level of expertise, and relevancy to the question or query.
Accuracy, i.e., explanations correctly reflect a system’s process for generating its output. Explanation accuracy is a distinct concept from decision accuracy. Explanation accuracy needs to account for the level of detail in the explanation. This second principle might be in contrast with the previous one: a detailed explanation may accurately reflect the system’s processing but sacrifice how useful and accessible it is to certain audiences, while a brief, simple explanation may be highly understandable but would not fully characterize the system.
Knowledge limits, i.e., characterizing the fact that a system only operates under conditions for which it was designed and when it reaches sufficient confidence in its output. This practice safeguard answers so that a judgment is not provided when it may be inappropriate to do so. This principle can increase trust in a system by preventing misleading, dangerous, or unjust outputs.
Software Frameworks Supporting Dimension#
Within the European Research Council (ERC) XAI project and the European Union’s Horizon 2020 SoBigData++ project, we are developing an infrastructure for sharing experimental datasets and explanation algorithms with the research community, creating a common ground for researchers working on explanations of black boxes from different domains. All resources, provided they are not prohibited by specific legal/ethical constraints, will be collected and described in a findable catalogue. A dedicated virtual research environment will be activated, so that a variety of relevant resources, such as data, methods, experimental workflows, platforms, and literature, will be managed through the SoBigData++ e-infrastructure services and made available to the research community through a variety of regulated access policies. We will provide a link to the libraries and framework as soon as they be will fully published.
Main Keywords#
Kinds of Explanations: Explanations returned by an AI system depend on various factors (such as the task or the available data); generally speaking, each kind of explanations serves better a specific context.
Feature Importance: The feature importance technique provides a score, representing the “importance”, for all the input features for a given AI model, i.e., a higher importance means that the corresponding feature will have a larger effect on the model.
Saliency Maps: Saliency maps are explanations used on image classification tasks. A saliency map is an image where each pixel’s color represents a value modeling the importance of that pixel in the original image (i.e., the one given in input to the explainer) for the prediction.
Single Tree Approximation: The single tree appoximation is an approach that aims at building a decision tree to approximate the behavior of a black box, typically a neural network.
Dimensions of Explanations: Dimensions of explanations are useful to analyze the interpretability of AI systems and to classify the explanation method.
Black Box Explanation vs Explanation by Design: The difference between Black Box Explanation (or Post-hoc Explanations) and Explanation by Design (or Ante-hoc Explanations) regards the ability to know and exploit the behaviour of the AI model. With a black box explanation, we pair the black box model with an interpretation the black box decisions or model, while in the second case, the strategy is to rely, by design, on a transparent model.
Model-Specific vs Model-Agnostic Explainers: We distinguish between model-specific or model-agnostic explanation method depending on whether the technique adopted to retrieve the explanation acts on a particular model adopted by an AI system, or can be used on any type of AI.
Global vs Local Explanations: We distinguish between a global or local explanation depending on whether the explanation allows understanding the whole logic of a model used by an AI system or the explanation refers to a specific case, i.e., only a single decision is interpretable.
Bibliography#
- 1
European Parliament & Council. General data protection regulation. 2016. L119, 4/5/2016, p. 1–88.
- 2(1,2,3)
P. Jonathon Phillips, Carina A. Hahn, Peter C. Fontana, Amy N. Yates, Kristen Greene, David A. Broniatowski, and Mark A. Przybocki. Four principles of explainable artificial intelligence. NISTIR 8312, September 2021. URL: https://doi.org/10.6028/NIST.IR.8312 (visited on 2022-02-16).
- 3(1,2)
M.T. Ribeiro, S. Singh, and C. Guestrin. "why should I trust you?": explaining the predictions of any classifier. In SIGKDD. 2016.
- 4
J. Angwin, J. Larson, S. Mattu, and L. Kirchner. Machine bias: there’s software used across the country to predict future criminals. and it’s biased against blacks. 2016. URL: https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing (visited on 2020-09-22).
- 5(1,2)
R. Guidotti, A. Monreale, S. Ruggieri, F. Turini, F. Giannotti, and D. Pedreschi. A survey of methods for explaining black box models. ACM computing surveys (CSUR), 2018.
- 6
High-Level Expert Group on Artificial Intelligence. Ethics Guidelines for Trustworthy AI. 2019. URL: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai (visited on 2022-02-16).
- 7
David Leslie (the Alan Turing Institute). Understanding artificial intelligence ethics and safety - a guide for the responsible design and implementation of ai systems in the public sector. URL: https://www.turing.ac.uk/sites/default/files/2019-06/understanding_artificial_intelligence_ethics_and_safety.pdf (visited on 2022-02-16).
- 8
Information Commissioner's Office (ICO) and The Alan Turing Institute. Explaining decisions made with AI. URL: https://ico.org.uk/for-organisations/guide-to-data-protection/key-dp-themes/explaining-decisions-made-with-ai/ (visited on 2022-02-16).
This entry was readapted from Pratesi, Trasarti, Giannotti. Ethics in Smart Information Systems. Policy Press (currently under review) and from Guidotti, Monreale, Ruggieri, Turini, Giannotti, Pedreschi. A survey of methods for explaining black box models. ACM Computing Surveys, Volume 51 Issue 5 (2019) by Francesca Pratesi.